Are you dealing with duplicate data records in HubSpot and not sure how to prevent this issue from happening again?

Duplicate data is a serious issue for any company using multiple platforms to manage their data. It occurs when an exact copy of a record is created as a different entry in the same database.
When you integrate HubSpot with a new platform or import records manually, there's a good chance you'll experience at least some data duplication, despite the fact that HubSpot does have some duplicate data detection systems in place. That's where Insycle steps in. Insycle is a modern data management tool that helps marketers organize and cleanse their data in HubSpot and other platforms
Before tackling duplicates using HubSpot and Insycle, it's important to first recognize the negative impact of duplicates, which depends on how numerous they are and where they occur. Duplicates in CRM records such as contacts, companies, and deals in HubSpot are not created equally, and each has their own concerns associated with them.
A study by Experian found that as many as 94% of organizations suspect that their customer and prospect data may be inaccurate. According to experts, duplication rates between 10%–30% are not uncommon for companies without data quality initiatives in place. Those duplicate records can affect a company in a variety of ways and result in measurable costs.
Why Duplicate Data Is Harmful
We’ve all dealt with duplicate data before. Whether we upload it ourselves into our CRMs through a data import function or mistakenly create a second entry manually, data is entered by a source from outside your company, or data is integrated from different source systems that bypass data validation rules.
And duplicate data is expensive. According to research from the Data Warehouse Institute, data quality problems cost U.S. businesses more than $600 billion every year.
Costs and lost productivity
The costs associated with data duplication are higher than you might think. Depending on where the duplicate records exist, the costs can really stack up. For example, duplicate customer records in a marketing database can eat into budgets when customers are contacted multiple times with the same marketing materials.
There are also costs associated with lost productivity. A customer service rep that must identify and deal with a customer having multiple records in your database is a time consuming and frustrating situation for both parties. A sales rep that calls the same customer multiple times due to data duplication also sees their productivity hindered and may annoy the customer with all those phone calls.
In one example, Children’s Medical Center Dallas worked with an outside firm to help them clean up their duplicate data. When they first began their engagement, Children’s Medical Center Dallas had a staggering data duplication rate of 22%. The firm helped them lower their duplication rate all the way to 0.2%. A later study revealed an average cost of $96 per duplicate record. With an initial data duplication rate of 22%, it’s easy to see how those costs would quickly add up.
Lack of a single customer view
The point of a CRM system is to provide you with a single customer view that helps you better manage your interactions with each customer. Having multiple customer records in your database makes a single customer view impossible. Companies with large numbers of duplicate customer records will never have a clear understanding of their interaction with those customers.
If you can’t tie your communications and transactions with a customer together, you lack the ability to speak honestly and accurately with them through personalized marketing communications. Even worse, your sales reps could hop on a call with them and be misinformed about their history with your company.
Wasted marketing budget
Having multiple duplicate records for your customers can eat into your marketing budget quite quickly. If you have five records for one customer and are planning on sending out a catalogue through direct mail, you'll send the catalogue to that same customer five times over. That's a huge waste on print and postage costs. Now imagine that same kind of waste across all your marketing campaigns—it’s easy to see how these costs could quickly start to add up over time.
Duplicate customer records in a marketing database is a very straightforward example of how data duplication can cost companies money. With large data integrity issues, there's no guarantee that your marketing data provides an accurate representation of the effectiveness of your marketing campaigns, which can hamper decision-making.
Suffering brand reputation
Duplicate data records can harm your brand reputation. Here’s an example: If you had one customer listed in your database 5 times, you may accidentally send them the same marketing materials 5 times. If the mistake goes unnoticed, they may receive many communications several times over. Over the course of 5 campaigns, you may accidentally end up contacting a customer 25 times.
This looks unprofessional and will likely harm your reputation in the eyes of that customer. According to a study by Gartner, annoying customers with the same materials multiple times results in a 25% reduction in potential revenue gains.
Also, data duplication is rarely limited to just a handful of customers. If you have serious data duplication issues, you may be harming your brand reputation with a larger percentage of your contact list than you might imagine.
Disjointed customer service
Duplicate records also impede your ability to offer a fulfilling customer service experience. If a customer calls, it will be much harder to resolve the issue if you have to dig through multiple duplicate records to find the right profile.
Their customer ID may be different from the one that shows up when you search for them in your database. Sometimes, duplicate records have some information missing, which can result in records that look like the “main” record, but have data missing from them.
Duplicate data doesn’t just make work harder for your teams internally. It’s also a frustrating experience for your customers as well. They may be forced to call several times to resolve a single issue or become frustrated when it seems like one customer support rep is seeing different information than the last one they spoke with—because they likely are. This frustration can build and lead to customers turning to competing companies that are able to offer a more consistent customer experience.
Storage costs
Data storage costs can be significant depending on the type of data you store, and duplicate records can occupy a lot of storage space. While you wouldn’t expect a CRM record to be duplicated hundreds or even thousands of times, consider other types of data that a company might store.
Consider an email attachment. Let’s say that a 1 MB email attachment was sent by 100 people within your company. With 100 instances of the attachment saved in your database, this requires 100 MB of storage space in total. By removing duplicate entries through data de-duplication, only one instance of the attachment is required to be stored, resulting in a total of 1 MB of space being occupied.
This goes for any business asset that may be saved, changed, or iterated many times—PowerPoint files, Word Documents, and PDFs. Companies that store large amounts of data with strict backup policies can see as much as 80% of their total corporate data duplicated.
Inefficiency and missed opportunities
Having multiple records for the same customer, regardless of the cause, leads to wasted time and confusion among your teams. Ultimately, mistakes will be made, and members of your team will move forward with incomplete information.
If two salespeople speak to the same person and create records for them in your CRM and later they engage with a customer service rep, which record should the rep add interaction notes to? Will the next rep choose the right record, or will they add notes to the duplicate record? If a customer has more than two duplicate records, your teams may end up sifting through a lot of data before they find the right data entry.
This is just one example of how duplicate data can lead to inefficiencies, but these issues will be present throughout all departments in your organization. Sales reps may contact prospects multiple times or record their notes in the wrong customer record. Marketing teams may send the same materials to a prospect multiple times or continue to send marketing materials to someone that has already become a customer.
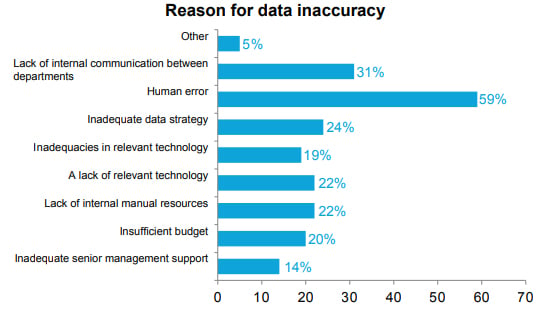
If your employees consistently run into these issues, they may lose confidence in their internal data, which will only further the problem. This lack of confidence can lead to employees cutting corners and more human error, which Experian found to be the leading cause of data accuracy issues in organizations:
What Is Data De-Duplication?
Data de-duplication refers to a series of techniques and strategies that are used to eliminate redundant data in a database. In a successful de-duplication campaign, extra duplicate copies of a record are deleted, leaving only one copy of the record in question.
Data de-duplication systems analyze byte patterns to identify duplicate copies of the same record. Typically, the extra copies are merged or deleted and replaced with a reference that routes back to the remaining permanent record.
The best data de-duplication solution for your company depends on the platforms you use and the type of data you collect. For HubSpot users, the platform has data de-duplication features built into the platform to help limit data duplication.
How Does HubSpot Handle De-Duplication?
HubSpot has automatic de-duplication for contact and company records. While there are many ways for duplicate records to appear in your HubSpot database, there are ways to decrease data issues.
HubSpot de-duplicates contacts in several ways:
Contact usertoken de-duplication
The usertoken is the cookie that HubSpot stores in a website visitor’s browser when they visit your webpage and load the HubSpot tracking code. HubSpot de-duplicates contact records using the usertoken and then evaluates whether the record should be merged with an existing contact record.
For example, if a user visits your site and fills out a form in their browser, then later another visitor uses the same computer and browser to submit the same form, the two records will share the same usertoken. HubSpot’s default action in this instance is to overwrite the information recorded on the first submission and prioritize the information sent on the second form submission. However, if the email address of the second submission matches an existing contact in HubSpot, the matching record will be updated with the new data.
Contact email de-duplication
HubSpot offers automatic contact data de-duplication through matching email values. If a contact exists with the same email address as a new one being added to the system, the new contact information will be applied to the already existing record.
Company domain and URL de-duplication
HubSpot also offers automatic de-duplication for company records. When a new company record is entered into the system, HubSpot scans for a record that has a matching Company domain name and will append any existing records with the new information. If the record does not include the Company domain name, then the system will attempt to match the Website URL property value to an existing record. Importing records with both these values blank can result in duplicate company records.
While these features are certainly useful for limiting data duplication in your HubSpot account, there are many ways in which duplicate data records can still make their way into the system.
Importing data from another system that already includes duplicates, human error, or entries with missing values (for example, when records don’t have emails and only phone numbers) can cause HubSpot’s automatic duplication detection system to miss duplicate entries. Additionally, HubSpot stores records for deals, tasks, sales, and customer support that all may experience duplication but have no built-in controls for de-duplication available.
How Insycle Can Help With Duplicate HubSpot Data
For situations where duplicate data slips past HubSpot’s internal controls, Insycle is here to help. Our system is designed to help companies organize, cleanse, and update data across multiple platforms—including HubSpot—from one convenient solution.
If you use HubSpot and struggle with duplicate records, there are a few ways our platform can help:
Identify and merge duplicate companies and contacts
When duplicate company and contact records sneak by HubSpot’s internal detection system, Insycle will help you catch them quickly. Our system automatically detects what may be duplicate contacts or companies by letting you match by any field within the HubSpot system. Then, you can choose to delete or merge the duplicate records.
Merging duplicate records within Insycle is simple. You select the fields that you want to use to locate duplicate records, then select the two duplicate entries:

Then, click the Merge button, and all relevant fields are re-assigned to the master record, including related records like activities, tasks, and calls. With just a few clicks, you have merged duplicate records without any data loss, as you're also able to pick which value to retain for each field.
Smart records matching for imports
One of the biggest causes of data duplication comes from importing data from another platform. Either the duplicate records already existed on that platform, or the import will create new records that aren’t detected by HubSpot’s internal data duplication controls.
Insycle solves this problem with smart records matching. Our system allows you to interactively match, validate, map, edit, and filter your data imports, ensuring that you never import duplicate data. You can pick any field to search for matching data and interactively map CSV columns to your HubSpot fields. Our smart records matching works whether you're importing completely new entries or updating existing entries in your database.
Find and fix missing values
Because the internal HubSpot de-duplication system uses specific fields for matching duplicate entries, records with missing field values can lead to duplicate data. If you have incomplete contact or company data, Insycle can help you identify and fix it. Our drag-and-drop system makes it easy to find fields with missing values. Then, you can use our inline Excel-style editor to fill empty fields with the correct data.
Free Yourself From Duplicate HubSpot Data
Duplicate data is a huge problem for any team. It can quickly lead to disgruntled prospects, wasted budgets, and lost productivity. While HubSpot does have some internal controls that help to catch and limit duplicate entries, there are times when duplicate records can slip through the cracks. Insycle helps companies that use HubSpot reliably catch and merge duplicate records and import data without worry.
Ready to get started? Learn more here about how Insycle can help with duplicate data in HubSpot.