

What is a web crawler
A web crawler — also known as a web spider — is a bot that searches and indexes content on the internet. Essentially, web crawlers are responsible for understanding the content on a web page so they can retrieve it when an inquiry is made.
You might be wondering, "Who runs these web crawlers?"
Usually, web crawlers are operated by search engines with their own algorithms. The algorithm will tell the web crawler how to find relevant information in response to a search query.
A web spider will search (crawl) and categorize all web pages on the internet that it can find and is told to index. So you can tell a web crawler not to crawl your web page if you don't want it to be found on search engines.
To do this, you'd upload a robots.txt file. Essentially, a robots.txt file will tell a search engine how to crawl and index the pages on your site.
For example, let’s take a look at Nike.com/robots.txt.
Nike used its robot.txt file to determine which links in its website would be crawled and indexed.

In this portion of the file, it determined that:
- The web crawler Baiduspider was allowed to crawl the first seven links
- The web crawler Baiduspider was disallowed to crawl the remaining three links
This is beneficial for Nike because some pages the company has aren’t meant to be searched, and the disallowed links won’t affect its optimized pages that help them rank in search engines.
So now that we know what web crawlers are, how do they do their job? Below, let's review how web crawlers work.
How do web crawlers work?
A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
A search engine's web crawler most likely won't crawl the entire internet. Rather, it will decide the importance of each web page based on factors including how many other pages link to that page, page views, and even brand authority. So, a web crawler will determine which pages to crawl, what order to crawl them in, and how often they should crawl for updates.
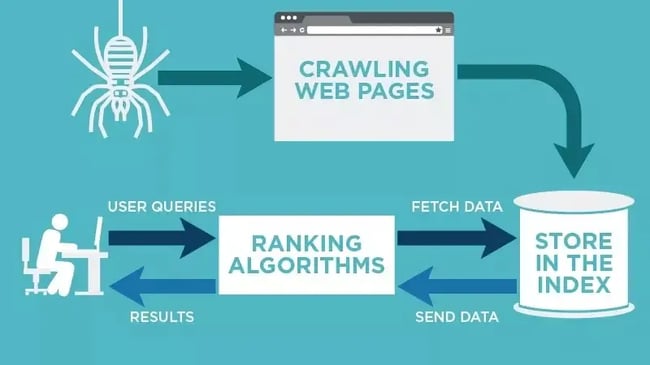
For example, if you have a new web page, or changes were made on an existing page, then the web crawler will take note and update the index. Or, if you have a new web page, you can ask search engines to crawl your site.
When the web crawler is on your page, it looks at the copy and meta tags, stores that information, and indexes it for Google to sort through for keywords.
Before this entire process is started, the web crawler will look at your robots.txt file to see which pages to crawl, which is why it's so important for technical SEO.
Ultimately, when a web crawler crawls your page, it decides whether your page will show up on the search results page for a query. It's important to note that some web crawlers might behave differently than others. For example, some might use different factors when deciding which web pages are most important to crawl.
Now that we’ve gone over how web crawlers work, we’ll discuss why they should crawl your website.
Why is website crawling important?
If you want your website to rank in search engines, it needs to be indexed. Without a web crawler, your website won’t be found even if you search for over a paragraph directly taken from your website.
In a simple sense, your website cannot be found organically unless it’s crawled once.
To find and discover links on the web across search engines, you must give your site the ability to reach the audience it’s meant for by having it crawled — especially if you want to increase your organic traffic.
If the technical aspect of this is confusing, I understand. That's why HubSpot has a Website Optimization Course that puts technical topics into simple language and instructs you on how to implement your own solutions or discuss them with your web expert.
How and Why to Crawl Your Site
If your site has errors making it difficult to crawl, it could fall lower in SERP rankings. You work hard on your business and content, but – as mentioned above – no one will know how great your site is if they can’t find it online.
Luckily there are crawling tools like Screaming Frog and Deepcrawl that can shed light on the health of your website. Performing a site audit with a crawling tool can help you find common errors and identify issues such as:
-
Broken links: When links go to a page that no longer exists, it doesn’t just provide a poor user experience, but it also can harm your rankings in the SERPs.
-
Duplicate content: Duplicate content across different URLs makes it difficult for Google (or other search engines) to choose which version is the most relevant to a user’s search query. One option to remedy this is to combine them using a 301 redirect.
-
Page titles: Duplicate, missing, too long, or too short title tags all affect how your page ranks.

You can’t fix problems on your site unless you know what they are. Using a web crawling tool takes the guesswork out of evaluating your site.
Types of Web Crawling Tools
There are plenty of tools on the market to choose from with various features, but they all fall into two categories:
-
Desktop: These tools are installed and stored on your computer.
-
Cloud: These tools use cloud computing and don’t have to be stored locally on your computer.
The type of tool you use will depend on your team’s needs and budget. Generally, choosing a cloud-based option will allow for more collaboration since the program won’t need to be stored on an individual’s device.
Once installed, you can set crawlers to run at a given interval and generate reports as needed.
Benefits of Using Web Crawling Tools
Having your site crawled properly is essential to SEO. In addition to diagnosing site errors, benefits of using a web crawling tool include:
1. Doesn’t Affect Site Performance
Site crawlers run in the background and won’t slow down your site when in use. They won’t interfere with your day-to-day tasks or have an effect on those browsing your site.
2. Built-in Reporting
Most crawlers have built-in reporting or analytics features and allow you to export these reports into an excel spreadsheet or other formats. This feature saves time and allows you to quickly dig into the results of your audit.
3. Utilizes Automation
A great feature of web crawlers is that you can set a cadence to have them crawl your site. This allows you to regularly track site performance without having to manually pull a crawl report each time.
Performing regular site audits with a crawling tool is a great way to ensure your site is in good health and ranking as it should.
Expand Your Reach With Web Crawling
Web crawlers are responsible for searching and indexing content online for search engines. They work by sorting and filtering through web pages so search engines understand what every web page is about. Understanding web crawlers is just one part of effective technical SEO that can improve your website’s performance significantly.
This article was originally published July 15, 2021, and has been updated for comprehensiveness.

Technical Seo









