Artificial intelligence is all the buzz these days. But how does it actually work? Over the next few weeks, we'll take you behind the scenes of HubSpot's artificial intelligence, one feature at a time.

Artificial intelligence. Machine learning. Natural language processing. If you’re on the internet today, you’ve seen the sensational headlines around these buzzwords. Make no mistake: AI could change our world.
But how should everyday businesses approach it? Recently, we asked you—our users—what you thought of AI. As it turns out, you’re not fooled by the catchy headlines. You’re curious to see what’s behind the buzzwords. Here’s what one HubSpot customer said:
There’s a lot of smoke and mirrors out there around AI. I'd like to understand what’s actually behind the technology… if a qualified individual can explain the technology behind AI, that elevates the product.
While my friends might debate my status as a “qualified individual,” as the product manager of artificial intelligence at HubSpot, I know all about HubSpot AI.
Over the next few weeks, we’ll walk you through how HubSpot AI actually works, one feature at a time. In today’s post, we’ll focus on the most recently released AI-powered tool: duplicate management.
Back up. What’s this tool again?
Duplicate data stinks. Finding dupes manually is hard. So we built a tool that uses AI to find duplicate contacts and companies for you and makes merging them easy, too. Since launch, HubSpot users have merged over 3 million contacts and companies. That’s a lot of efficiencies gained. The duplicate management tool is available to Professional and Enterprise accounts across hubs.
Access Your Contacts in HubSpot
Why is duplicate data a good fit for AI?
When looking for problems that can be solved with artificial intelligence and machine learning, it's best to start with a rules-based approach. Can the problem be solved (or mostly solved) using a set of simple rules? If so, it's a great fit for AI.
In the example of duplicate data, the easiest way to find duplicates is to write a rule saying something like: for a contact, if the first name and last name of two contacts are the same, then this contact is a duplicate. This simple rule might catch 80% of duplicates, but the other 20% will slip through the cracks.
That's where AI and ML come in. For rules-based problems with a small set of "fuzzy" decisions, you can use AI to optimize the quality.
Sometimes, these rules truly do catch enough of the cases and AI isn’t necessary. In the case of duplicate records, there are enough fuzzy decisions that writing a machine learning algorithm outperformed our rules in performance and speed.
Why is finding duplicates hard?
Imagine we handed you 1000 marbles of all different colors and sizes, and asked you to figure out if any two were exactly alike. How would you go about doing it?
It wouldn’t be hard to do a mediocre job. Do a quick scan across all thousand, and pull out any matches you might spot. But to truly solve the problem—to find every single matching pair—you’d have to compare every marble to every other. Pick one, and compare it to the next 999. Then pick the next, and compare it to the next 998 (since you’ve already compared it to the first). And so on. That’s a lot of comparing.
As it turns out, you’d have to compare 500,000 unique pairs of marbles to get the job done. As you add more marbles, it takes exponentially longer to compare them all. Jump to 10,000 marbles, and you’d need to compare 50 million unique duos to find all the pairs.
Similarly, when computers look for duplicates of a certain piece of information, they have to compare every data point against every other, to make sure they’re not missing any duplicates. Just like bigger piles of marbles, larger data sets take exponentially more time to sort through.
While computers are faster than the human eye, comparing data takes time. In the context of your CRM, a HubSpot account with fifteen thousand contacts will take about a day and a half to find duplicates, while an account of 1.5 million contacts could take up to thirty-five years.
There are workarounds—just like in counting marbles—but shortcuts lead to missed duplicates. For example, you could download a spreadsheet of all your contacts, and find all the ones with the exact same first and last names. But, like we talked about above, a rules-based approach will miss a chunk of duplicates.
Long story short, you can’t wait 35 years for HubSpot to find your duplicates, nor can you afford to take shortcuts. So what’s the solution?
How does it actually work?
Rather than compare every contact to every other, HubSpot uses a machine learning model that clusters contacts based on how similar they are, and selects only the closest pairs. Models are the core of what makes machine learning work. Standard computer algorithms are created by a programmer using a series of if/else statements - the "rules-based" approach we outlined above. A model is a special type of algorithm trained by feeding in examples until the computer can recognize a pattern and reliably predict an output. In our case, our model spits out the probability that two contacts are duplicates based on historical examples.
For contacts, the model considers the fuzzy matches (not exact match, in case a name is misspelled) between name, email(s), IP country, phone number, zip code, and company name. For companies, the model looks at name, domain, country, phone, industry.
The contacts are then sorted by their probabilities of being a duplicate and displayed in your tool, in that order. With that in mind, you may notice that the deeper into the list you get, the less likely the records are to be duplicates.
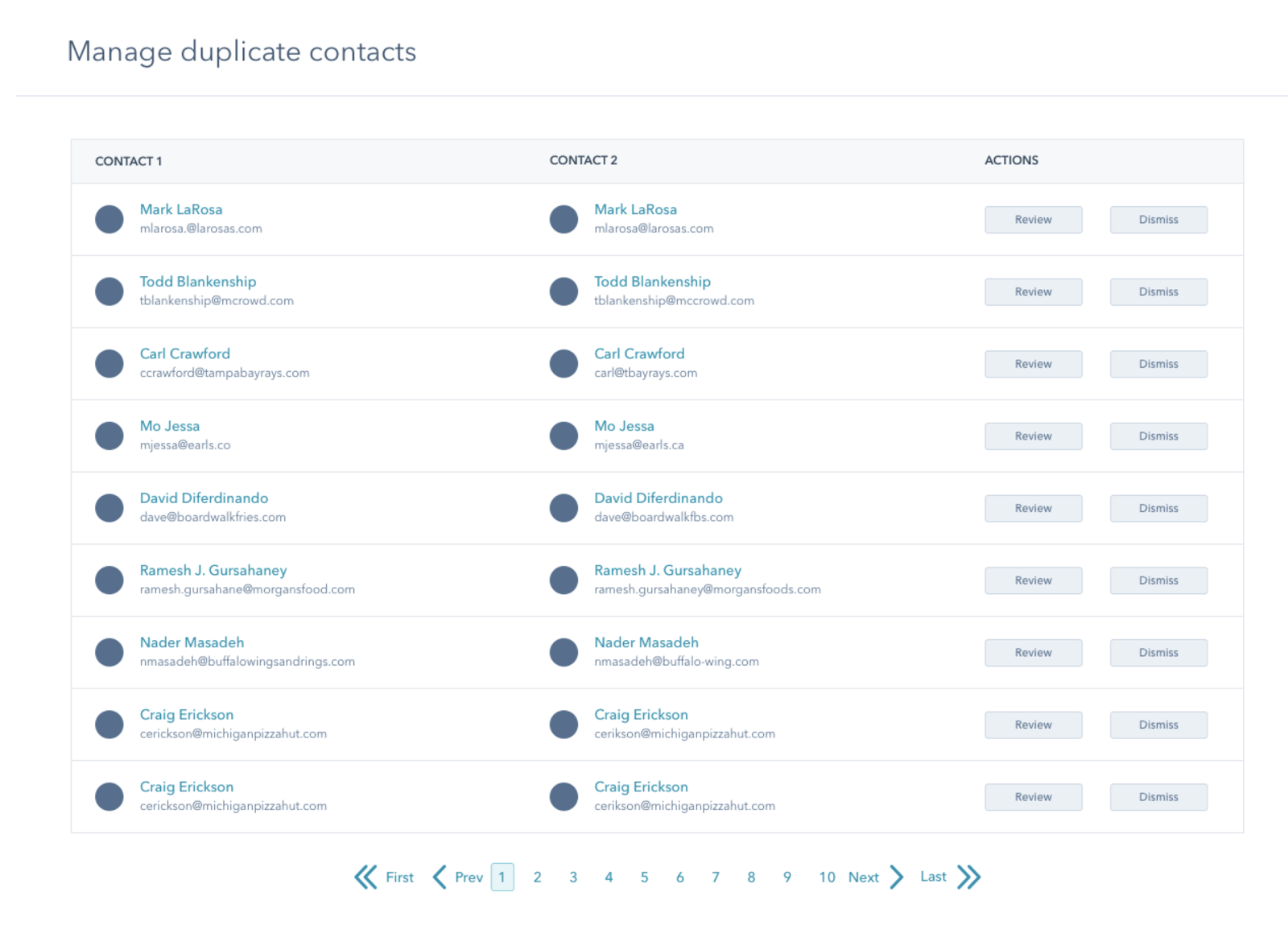
When you accept (merge) or reject (dismiss) a pair as duplicates, you’re providing feedback to this model by giving it more examples to look at - so it can more accurately predict the probability that two records are duplicates.
Access Your Contacts in HubSpot
Calculating this probability still takes time. That’s why the process only runs every two weeks, but it’s exponentially faster than the alternative.
A month ago, the number of duplicates changed. What happened?
Our initial assumption when releasing this tool was that you'd want to see all pairs of contacts and companies that had a good chance of being duplicates—even if it meant that some portion wouldn’t be duplicated. Over the last few months, your feedback has been loud and clear: seeing pairs of contacts and companies that are not duplicates in a tool designed for duplicate management is confusing.
With that in mind, we raised the probability threshold. In other words, you’ll only see pairs with a high chance of being duplicated. It’s a tradeoff: the lower the probability threshold, the more likely you’ll be to catch every single pair of duplicates, but the more noise you’ll have to cut through to find them. We’re always looking to optimize both your data integrity and your team’s efficiency - with that in mind, we’re open to any and all feedback on the tool.
What's next
The AI behind the duplicate management tool is critical to its use, but it doesn’t make the tool valuable on its own. If what’s “in front of the curtain” is clunky, what’s “behind the curtain” doesn’t matter. With that in mind, in addition to an ever-improving AI model on the back end, you’ll be seeing a slew of usability improvements that make the duplicate management tool more of a joy to use.
Here are three new features that you can expect to see in your duplicate management tool soon:
- Choose which properties to compare. Previously, when comparing two contacts or companies, you'd only see three properties on either record. But not all companies use properties in the same way. You may have a set of custom properties that are better indicators of a contact's quality. With a recent change, you can now add any properties to the comparison modal, to help you choose the right record faster.
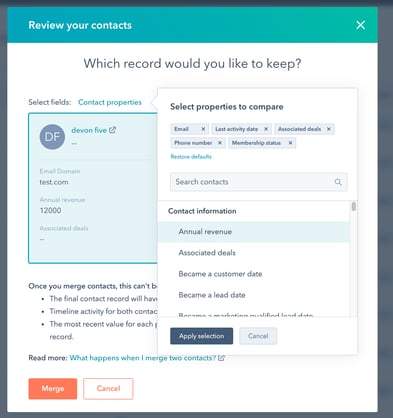
- Get a better idea of when updates will run next. Updates run every few weeks; when you navigate to the tool, you'll now be alerted when the next update will run.

- Get alerted when new duplicates are found.
