What is a materialized view?
Materialized views are pre-computed data sets responsible for replicating databases to other websites. This means you won’t need to run expensive queries every time you retrieve information from a database. Materialized views store their output data, which means pulling information is faster than running queries directly on a table.
This probably sounds like a lot of jargon, so let’s work through an example to make the idea feel real.
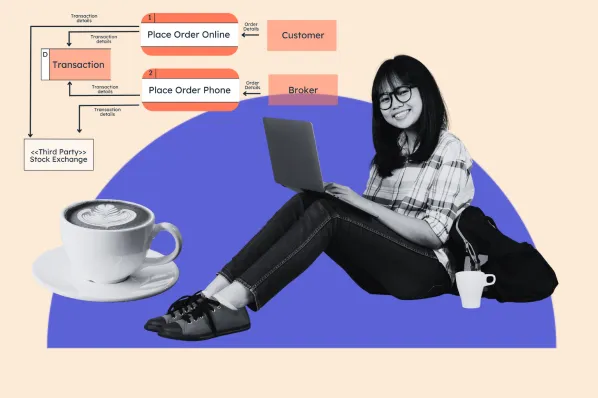
Imagine I have three base tables: Staff, Items, and Sales. The Items table stores records of different items. In this case, we’re looking at different kitchen appliances. Meanwhile, the Sales table contains sales records for each item, using a foreign key, itemId, in the Sales table.
I can create a materialized view named sales_by_item, which aggregates the total sales per item. This can be done either directly from the Sales table or through a JOIN statement that references both the Items and Sales tables. This can be helpful I need more detailed data in the view.

When to Use Materialized Views
In real-world systems, materialized views are beneficial in four key areas:
- Easing network loads.
- Creating a mass deployment environment.
- Enabling data subsetting.
- Enabling disconnected computing.
Below, I’ll discuss each of these use cases so we can see why materialized views support these goals.
Easing Network Loads
Organizatiosn that operate in multiple locations rely heavily on networks for communication. However, the more people that use my system, the more strain it experiences. To avoid the need for costly network upgrades due to higher traffic, I can instead reduce network traffic.
Read-only materialized views have been a game-changer in helping distribute network loads. By replicating databases in various geographical areas closer to where employees work, I can prevent data conflicts in the source database. This approach is much more efficient than having the entire company access data from a single server.
With multiple servers in different locations, your materialized view will operate from whichever server is closest to you. Less distance traveled means information loads faster, and queries are completed more quickly. You can avoid increasing your storage costs and a number of speed-related headaches.
I can update these materialized views through an efficient batch process from a single source or main materialized view site. This process has fewer network requirements and dependencies, replicating only a specific point in time and requiring only periodic refreshes.
Furthermore, I can create materialized views based on other materialized views. This strategy allows me to distribute user load even more effectively. Clients can access materialized view sites instead of source sites. This further decreases the amount of data that needs to be replicated.
Creating Mass Deployment Environments
As a database administrator, mass deployment tools allow me to rapidly deliver database infrastructure and data. That means I can manage information across different sites while maintaining data quality.
Materialized views are easy to define using deployment templates. This means they are particularly supportive in mass deployments. By using these templates, I can specify the structure of a materialized view's environment once. Then, I can replicate it across multiple sites instead of reinventing the wheel.
I can also adjust template parameters, allowing me to customize each materialized view environment. This flexibility makes it easier to share specific data types with different data consumers.
Mass deployments through materialized views let me quickly distribute information to various endpoints. That means I can send data to field technicians, remote inventory sites, retail stores, and mobile sales forces. This approach significantly enhances my efficiency.
Enable Data Subsetting
I can use materialized views to replicate a subset of data from a source through row-level or column-level subsetting. This means I spend less money replicating data specific to certain sites. This approach is more efficient than the alternative, which would require complete table replication.
Data subsetting allows me to create copies that contain only portions of the entire database. I can then focus only on what information I need.
For instance, let’s say I have an organizational database containing employees in multiple departments. I can use materialized views to replicate data specific to one department for internal use.
This method also allows me to enforce a degree of security through materialized views and subsetting. I can make sure that only relevant data is exposed to authorized personnel.
Enable Disconnected Computing
Since materialized views are derivations of (mostly) live databases, I don‘t need dedicated network connections for them to work. In my standard practice, especially when using localized applications, I often opt for manual refreshing of materialized views. However, it’s possible to automate this process through job scheduling.
Manually refreshing my materialized view on-demand, as opposed to using a continuous data stream, has worked well for sales applications running on a personal computer.
For instance, as a developer, I can integrate the replication management API for refresh on-demand into a sales application. When a salesperson has completed the day's orders, they simply dial up the network and use the replication management API to transfer the orders to the primary office. A network connection is only needed during the refresh process.
Best Practices for Materialized Views
Just like with standard queries, I find it necessary to optimize materialized views. The base relations of most databases I work with are constantly changing in response to application-level transactions.
In my experience with materialized views, performance can be clunky if the view requires constant updating to reflect changes in base relations. To manage this, I can achieve better results by redefining the initial expressions that generated the materialized views.
We’ll dive into this best practice, among others, below.
Creating materialized views
When I create materialized views, I make it a point to prioritize resource-intensive processes. This strategy allows views to store data types that reduce the need for frequently performing complex queries. That means you save time and, more importantly, power.
Additionally, I‘ve found that you can derive more than one materialized view from the same base relation. One view might hold a table’s most recent data, while another captures unusual data from the same relation. Using a non-materialized view, I can join these two, even though they were initially created as materialized views.
The resulting view is quite insightful, often revealing data anomalies that could indicate critical issues like denial of service (DoS) attacks on databases.
In my practice, I consider building a materialized view for unusual data only in databases where base relations are unclustered. I’ll also use this method if I've already specified columns containing unusual data within the base tables’ clustering keys.
Furthermore, I opt for materialized views for unusual data only if it‘s easy to isolate isolable. I’ve learned that the cost of maintaining materialized views for data that's rarely used can outweigh the benefits.
Optimizing base table operations
As I noted earlier, a common challenge I face when working with materialized views is the potential inconsistencies between them and the regularly updated base table. To address this issue, I consider batching the data manipulation language (DML) operations on the base table.
For instance, using the DELETE operation is a common practice for me to trim old data from tables. If I have materialized views based on such tables, updating them to reflect these changes is essential. However, frequent updates can increase background performance and storage costs. To manage these costs, I execute batch delete operations on tables weekly or monthly.
For other procedures like INSERT, MERGE, and UPDATE, batching them on base relations in my databases has also proven effective in reducing the maintenance costs for materialized views derived from these tables.
Beyond just creating materialized views, I also create view logs and custom on-demand view refreshes. I'm aware that there are far more complex operations that can be defined in Oracle and other databases for materialized views. To learn more, you can check out this handyguide.
Streamline Data Analysis With Materialized Views
I can't overemphasize how much value materialized views add to database-driven systems. They reduce performance bottlenecks and costs that come with running native queries on databases. That’s big savings in production environments where stored data can be expansive.
I always consider materialized views when supplementing resource-intensive queries. Additionally, batching DML operations on databases is a strategy I employ to reduce performance costs. This approach has significantly enhanced the efficiency of the database systems I manage, and I hope this method helps you too.
Editor's note: This post was originally published in October 2022 and has been updated for comprehensiveness.

Data Management
-1.png)